
Creamos un descompresor recursivo automático de archivos en Bash
3/31/202518 min read

Nuevamente accedemos a bandit con el usuario bandit12 con el siguiente comando:
$ sshpass -p '7x16WNeHIi5YkIhWsfFIqoognUTyj9Q4' ssh bandit12@bandit.labs.overthewire.org -p 2220
Y como ya sabemos volvemos a aplicar xterm para poder limpiar la terminal con facilidad...


Y volvemos a ver la página de OverTheWire el nivel 12 -> 13 A ver que instrucciones nos dan. Como podemos comprobar la contraseña se almacena en el archivo data.txt pero esta volcado en hexadecimal en un archivo comprimido repetidamente. Entonces vamos a ver como podemos conseguirla...
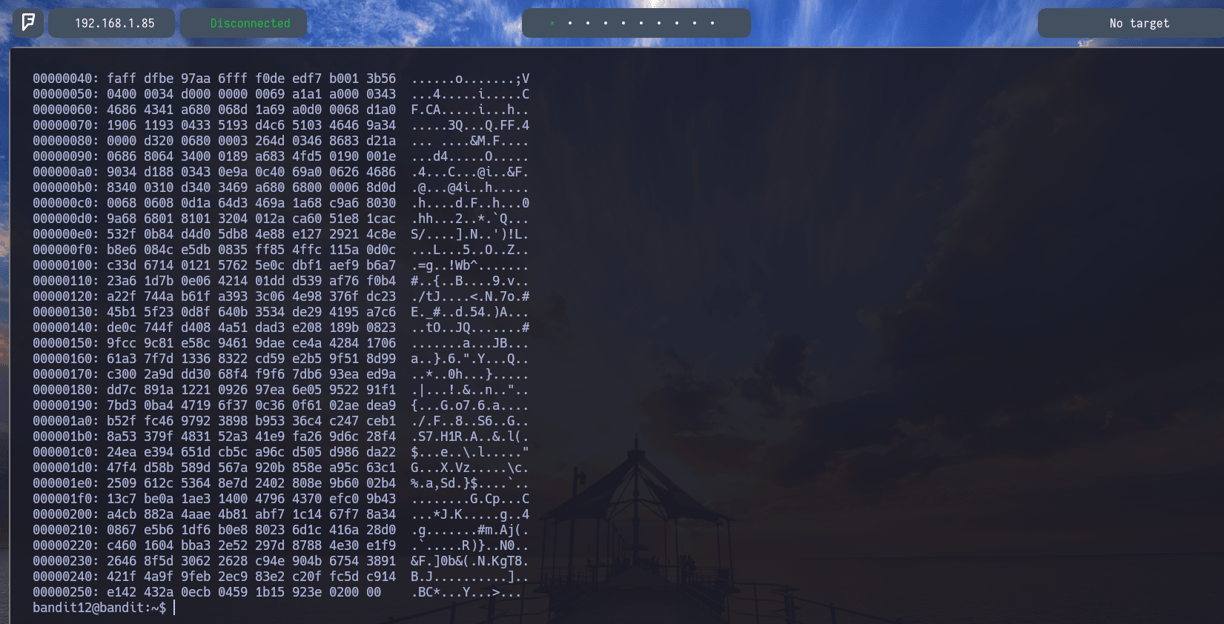
Como observamos si hacemos un cat data.txt el archivo es hexadecimal como hemos visto anteriormente... ¿ Y esto que significa?
El sistema hexadecimal es un sistema de numeración posicional que utiliza 16 símbolos diferentes:
Los dígitos del 0 al 9, representando los valores del 0 al 9.
Las letras A, B, C, D, E y F, representando los valores del 10 al 15.
Este sistema es una extensión del sistema decimal, que usa solo 10 dígitos, y del sistema binario, que usa solo 2. Cada posición en un número hexadecimal representa una potencia de 16, lo que permite representar números muy grandes con pocos dígitos.
Por ejemplo, el número hexadecimal 2F3 representa:
2×162+15×161+3×160=755 en decimal
Realmente lo que interesa del archivo que vemos en la imagen es lo que hay en el centro, lo que hay en la izquierda o a la derecha es relativo en este ejercicio. Lo importante son los caracteres hexadecimales del centro.
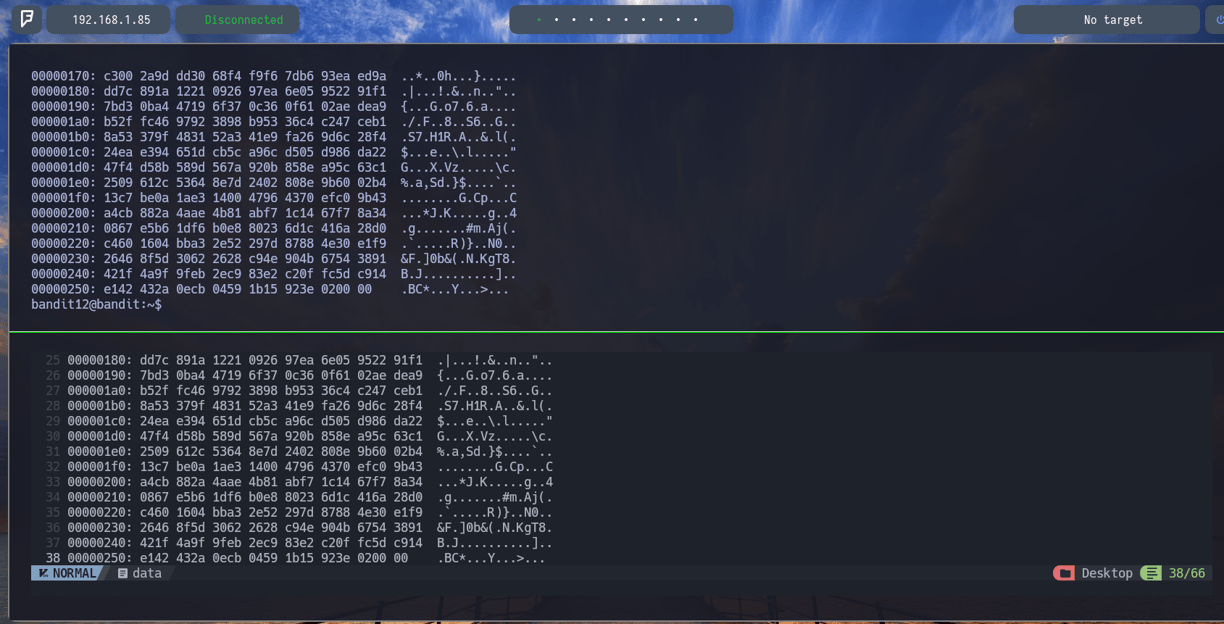
Ahora igual que vimos con los archivos en base64 que transformábamos y los des transformábamos a base64, debemos hacer los mismo con los archivos hexadecimales, deberíamos transformarlo para ver que es lo que se ha convertido en hexadecimal para poder lograr la contraseña...
Entonces lo que haremos será, copiarnos todo el contenido del archivo dentro de un archivo a nuestro gusto. En mi caso al archivo data, como vemos en la imagen superior, me lo copio dentro de mi máquina local, fuera del servidor ssh

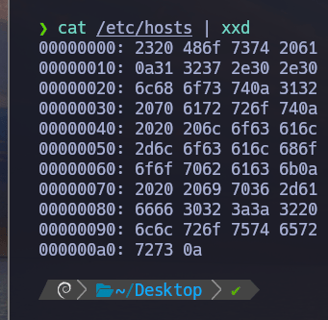
$ cat /etc/hosts | xxd - Nosotros ahora podemos jugar con xxd, xxd es un comando que nos permite convertir archivos a hexadecimal o a archivos no hexadecimales, es decir a su valor original... Tal y como vemos en la imagen si solo aplicamos xxd lo convertirá en hexadecimal al archivo /etc/hosts.

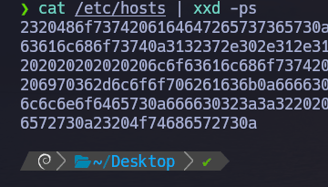
$ cat /etc/hosts | xxd -ps Ahora podemos agregarle el parámetro -ps para indicar que en el output, lo que aparece en la parte de la izquierda y de la derecha no queremos verlo, ya que es innecesario y molesto... Así que como output únicamente veremos los valores hexadecimales...

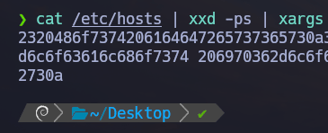
$ cat /etc/hosts | xxd -ps | xargs Ahora podemos compactar todo el texto hexadecimal en una sola línea con xargs

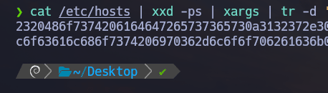
$ cat /etc/hosts | xxd -ps | xargs | tr -d ' ' Y por último podemos agregarle tr -d ' ' para con el parámetro -d ' 'podemos eliminar los espacios que vemos en la línea

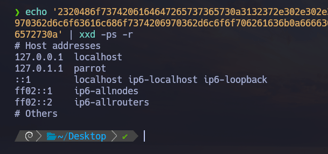
$ echo "2320486f7374206164647265737365730a3132372e302e302e3120206c6f63616c686f73740a3132372e302e312e312020706172726f740a3a3a3120202020202020206c6f63616c686f7374206970362d6c6f63616c686f7374206970362d6c6f6f706261636b0a666630323a3a31202020206970362d616c6c6e6f6465730a666630323a3a32202020206970362d616c6c726f75746572730a23204f74686572730a" | xxd -ps -r
Entonces nosotros si nos copiamos toda esa línea y hacemos un echo de esa línea agregándole el comando xxd -ps -r donde el parámetro -ps era para eliminar el conjunto de la izquierda y de la derecha para quedarnos solo con el del centro que sería el hexadecimal, y sumándole el parámetro -r de reverse para realizar el proceso inverso a transformarlo a hexadecimal, que sería devolver el archivo a su estado original... Como vemos en la imagen superior

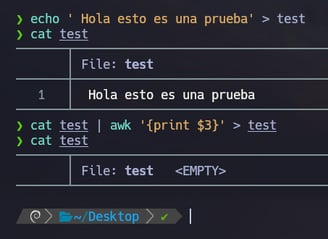
Como vemos en el ejemplo de la pantalla, os voy a explicar algo muy básico de linux. Nosotros a la hora de sobrescribir un archivo si lo hacemos de esta manera:
$ echo 'Hola esto es una prueba' > test ( Insertamos el contenido dentro del archivo test )
$ cat test ( Vemos el contenido del archivo, y observamos el contenido 'Hola esto es una prueba' )
$ cat test | awk '{print $3}' > test ( Con esto cogemos el tercer argumento del contenido del archivo, que sería la palabra es. Y seguidamente la insertamos nuevamente dentro del archivo test. Para poder sobrescribirlo )
$ cat test ( Vemos que se elimina todo el contenido )
Con esto podemos entender que si lo hacemos de esta manera lo único que lograremos será eliminar todo su contenido

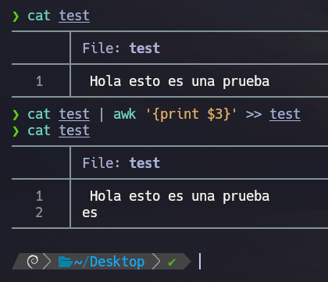
Si ahora volvemos a realizarlo pero en lugar de aplicarle solo 1 flecha > le aplicaremos 2 flechas >> pero lo único que lograremos será agregar la palabra es en otra línea. Y no lo que queremos es que solo aparezca la palabra es dentro del archivo... Así que vamos a probar de la siguiente manera...

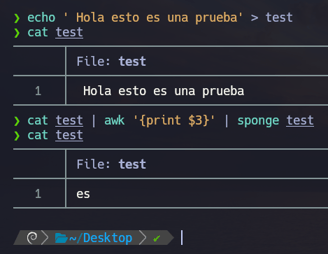
$ cat test | awk '{print $3}' | sponge test - Podemos utilizar el comando sponge, sponge es una herramienta útil a la hora de querer hacer lo que buscamos, ya que con los comandos que hemos visto anteriormente no podríamos Aplicando un sponge lo que hacemos es reemplazar todo el contenido del archivo actual por el que le estamos indicando con awk. Es decir queremos que cambio todo el contenido que haya dentro del archivo test por la palabra es. Y como vemos en la imagen superior funciona...

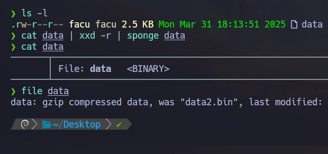
Entonces una vez hemos aprendido lo anterior, vamos a aplicarlo al archivo data que tenemos en nuestra máquina local.
$ cat data | xxd -r | sponge data ( Nosotros únicamente realizando xxd -r ya nos transforma el archivo completo a su estado original y sumándole sponge introducimos ese contenido en si mismo para transformarlo y no tener que crear otro paralelo... )
$ file data - Como observamos si le aplicamos un file nos muestra que estamos delante de un archivo comprimido en gzip.

¿ Y como sabe el comando file que estamos frente a un archivo gzip ? Pues de la siguiente manera... Para empezar nos instalamos ghex una utilidad para entender de donde proviene que el comando file por ejemplo sepa a que nos enfrentamos... Y nos lo instalaremos con el siguiente comando:
$ apt install ghex -y
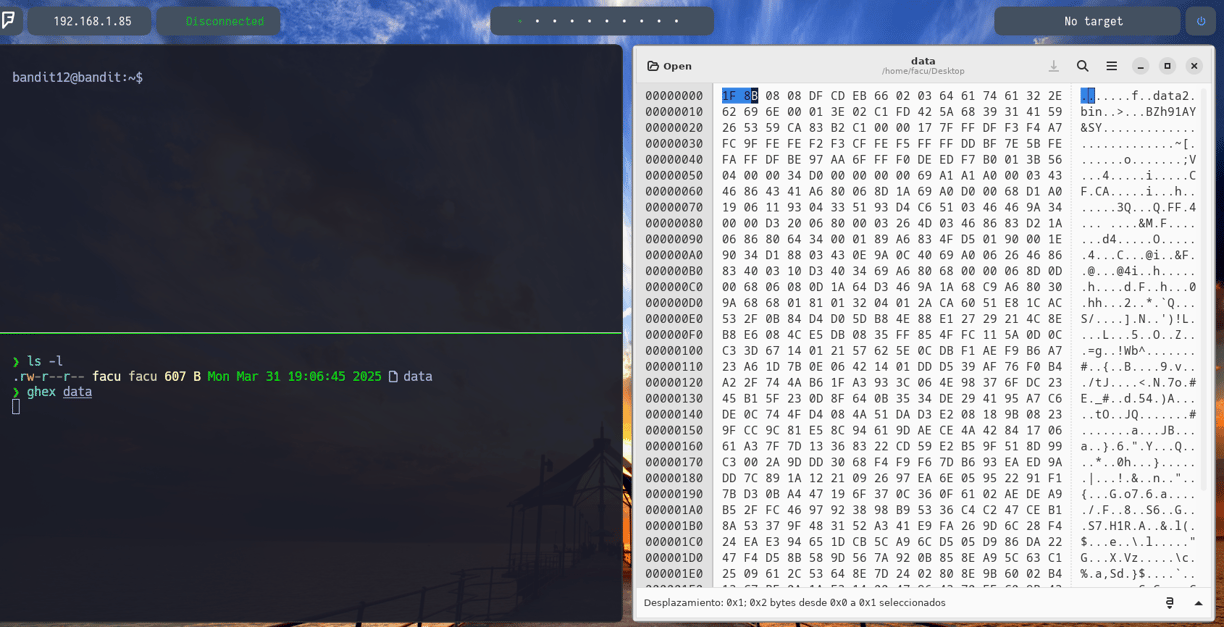
Pues es muy sencillo si aplicamos el comando $ ghex data ghex sobre el archivo data, veremos lo siguiente que vemos a la derecha. ¿Pero como veo que tipo de archivo es? Pues muy fácil, si cogemos los primeros 2 dígitos del archivo que vemos a la derecha son 1F 8B. Si ahora nosotros accedemos a la siguiente página web https://en.wikipedia.org/wiki/List_of_file_signatures Y filtramos por 1F 8B podremos ver lo siguiente:

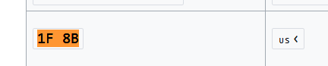
Ya podemos comprobar que se trata de un archivo GZIP comprimido

Entonces como es un archivo GZIP podemos cambiarle el nombre con el comando $ mv data data.gz para agregarle su respectiva terminación, como vemos en la imagen.
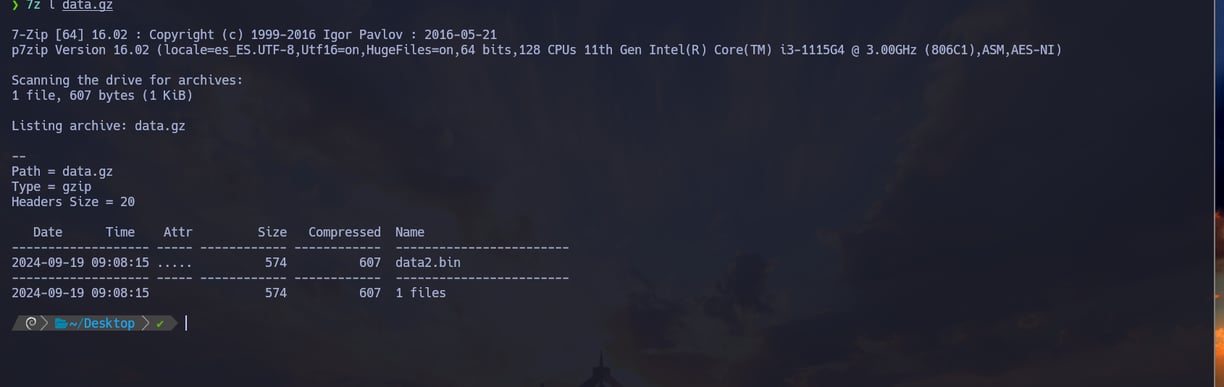
$ 7z l data.gz - Para poder descomprimir un archivo recomiendo utilizar 7z una herramienta para poder descomprimir todo tipo de archivos y que nos permite hacer lo siguiente: Con el parámetro l le indicamos a 7z que queremos listar el contenido del archivo data.gz Y podemos ver que nos indica que dentro hay otro archivo data2.bin como podemos comprobar...
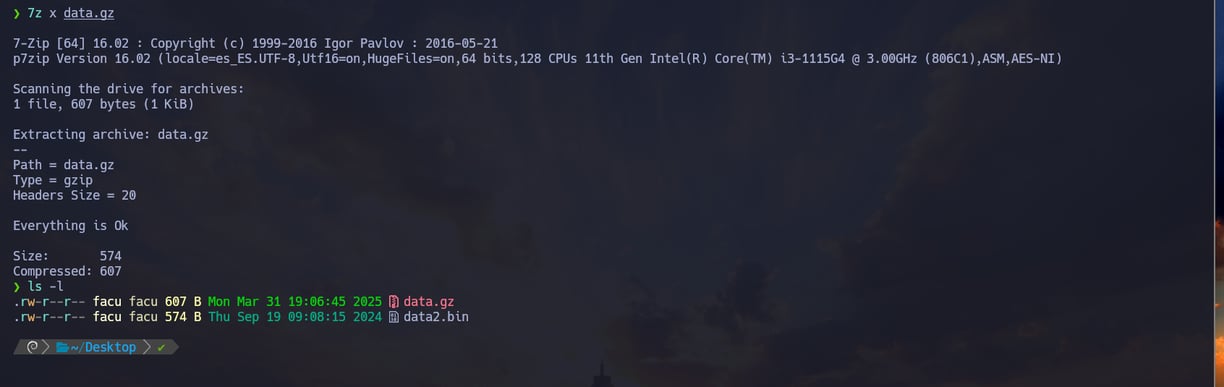
$ 7z x data.gz - Ahora si le aplicamos 7z sumándole el parámetro x podemos descomprimir todo el contenido que hay dentro del archivo independientemente de que tipo de compresión se trate...

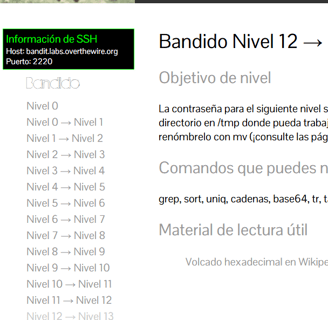
Ahora viendo nuevamente la página de OverTheWire, nos indica que tenemos que ir descomprimiendo repetidas veces los archivos hasta dar con la contraseña. Por lo tanto vamos a comprobarlo...
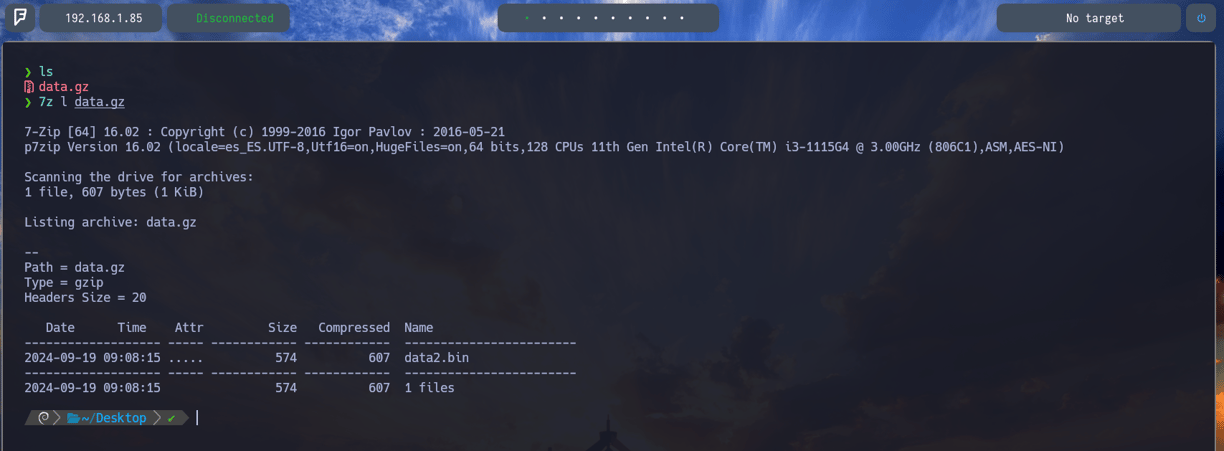
$ 7z l data.gz - Utilizaremos para esta práctica una herramienta bastante útil para poder descomprimir cualquier tipo de archivo, la herramienta es 7z y utilizándola junto al parámetro l podemos listar el contenido que tiene dicho comprimido antes de descomprimirlo. Y como podemos ver en la imagen dentro del archivo data.gz nos encontramos con el archivo data2.bin. Pues vamos a descomprimirlo...
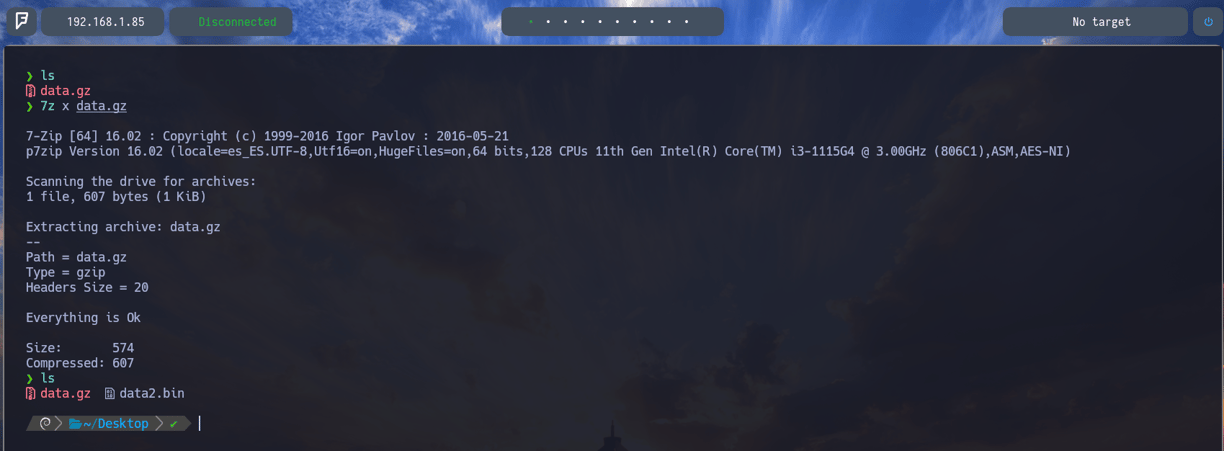
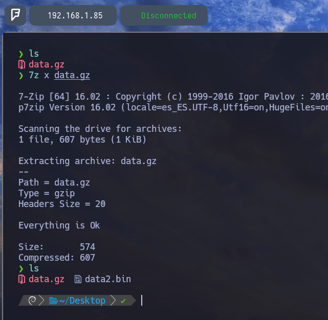
$ 7z x data.gz - Como vemos utilizando el parámetro x de la herramienta 7z podemos descomprimir cualquier archivo independientemente de su extensión final... Y si aplicamos el comando ls podemos comprobar que ya esta descomprimido en la ruta actual data2.bin.

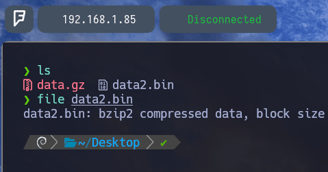
$ file data2.bin - Ahora si le aplicamos un file al archivo nuevo podemos observar que se trata de un comprimido bzip2 por lo tanto vamos a comprobar que nos encontramos dentro del archivo data2.bin
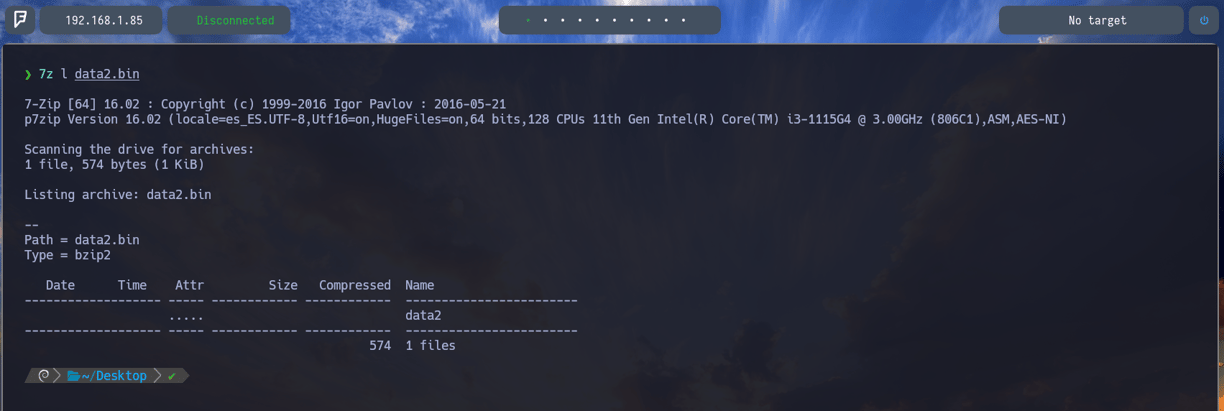
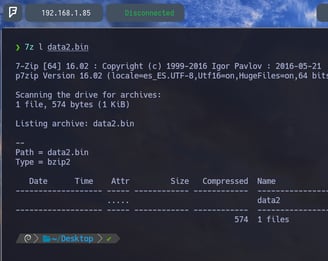
$ 7z l data2.bin - Ahora volvemos a listar el contenido del archivo nuevo data2.bin y como podemos observar nos encontramos con un nuevo archivo en su interior data2. Pues vamos a descomprimirlo como ya sabemos...
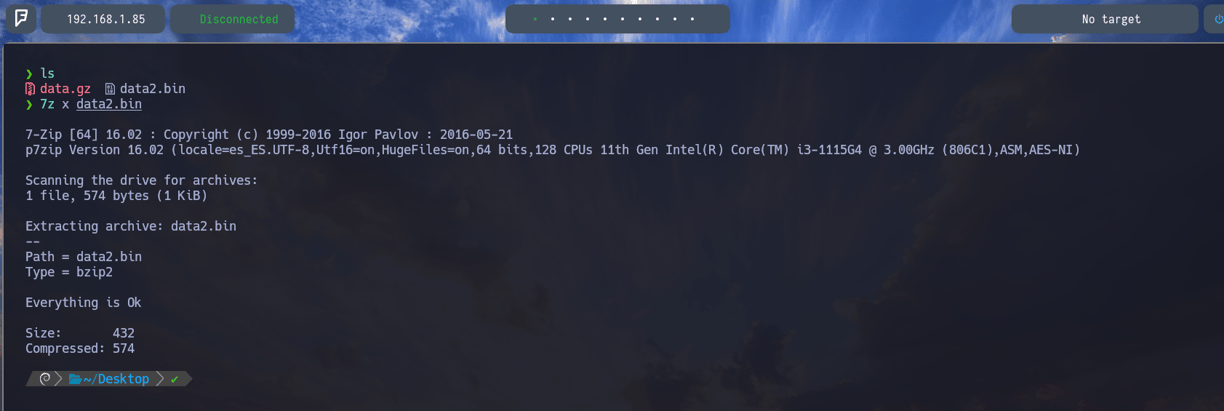
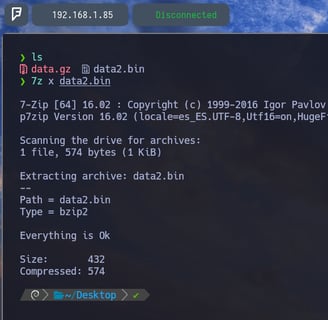
$ 7z x data2.bin - Aplicamos la descompresión igual que antes con 7z x y vamos a ver que nos encontramos

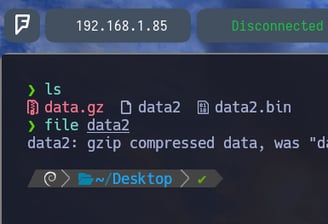
$ file data2 - Para nuevamente volver a comprobar ante que archivo nos enfrentamos... Y como podemos ver, es un archivo comprimido tipo gzip. Pues vamos a aplicar lo siguiente...
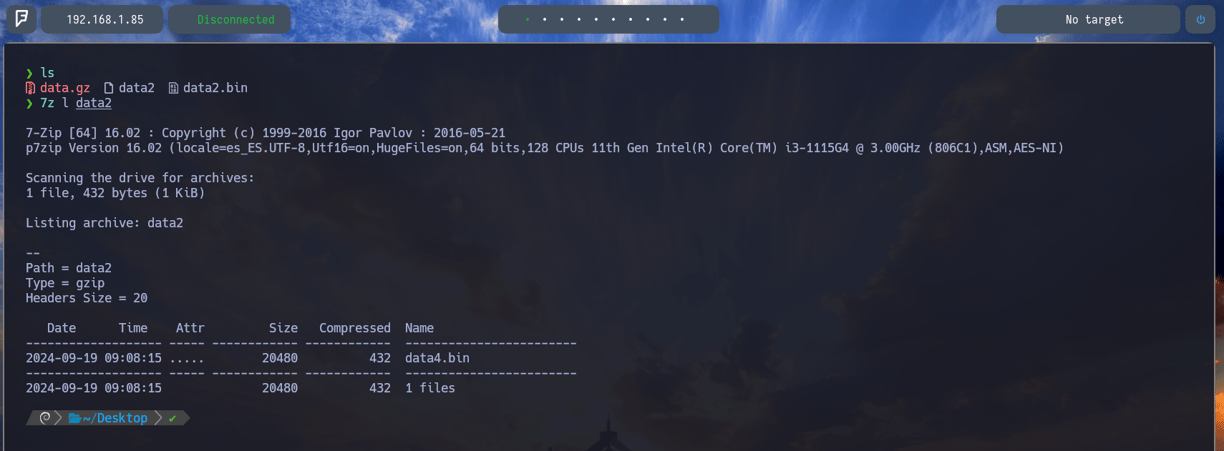
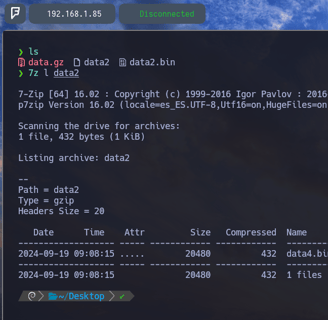
$ 7z l data2 - Para nuevamente comprobar que hay en el interior del archivo data2 y como podemos ver nos encontramos con el archivo data4.bin. Por lo tanto vamos a descomprimirlo nuevamente...
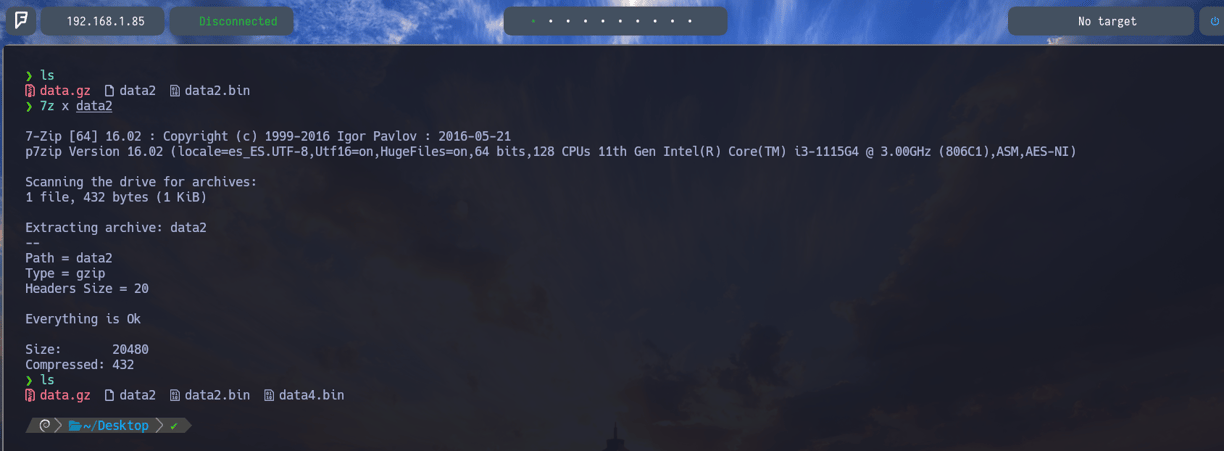
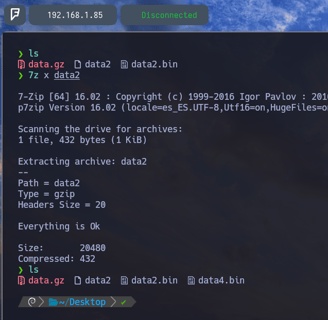
$ 7z x data2 - Lo descomprimimos nuevamente con 7z x y vemos que ahí tenemos el nuevo archivo data4.bin.

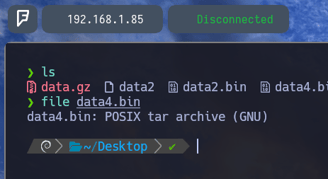
$ file data4.bin - Ahora le volvemos a aplicar un file al archivo para poder comprobar ante que nos enfrentamos, y como podemos observar, es un archivo comprimido de tipo tar...
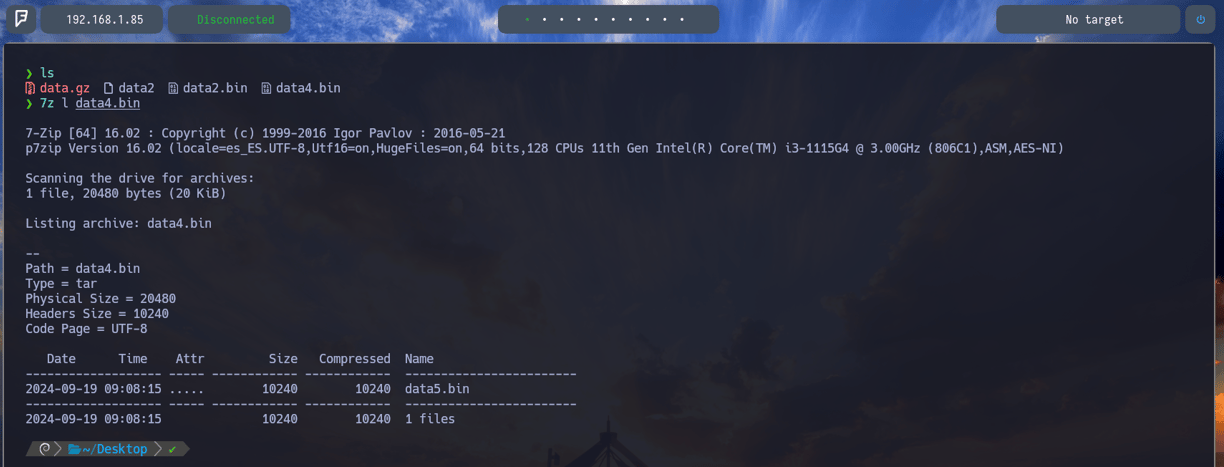
$ 7z l data4.bin - Ahora volvemos a comprobar que nos encontraremos dentro de este comprimido con 7z l y como podemos observar vemos el archivo nuevo data5.bin. Así que vamos a descomprimirlo...
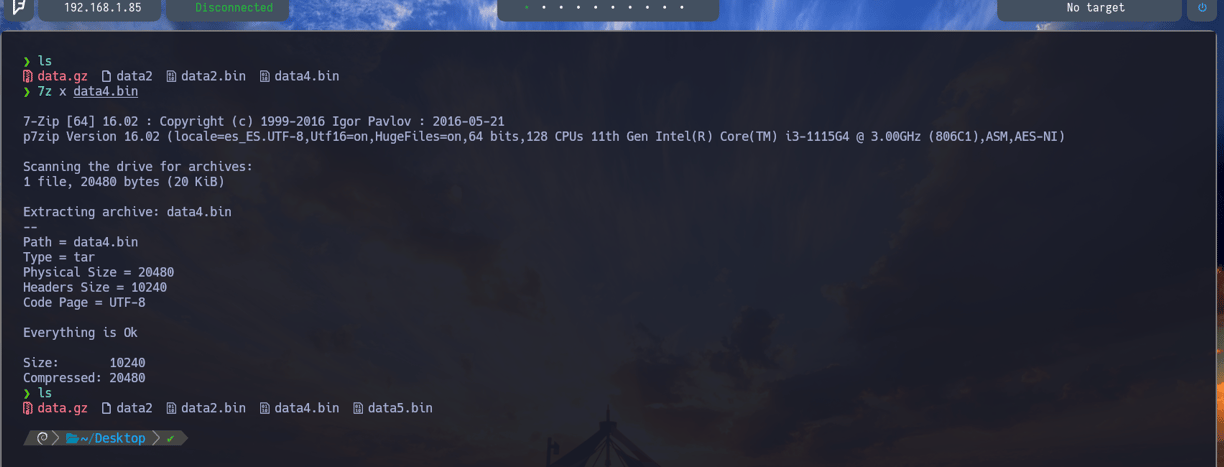
$7z x data4.bin - Lo descomprimimos y nuevamente observamos que tenemos un nuevo archivo. Data5.bin

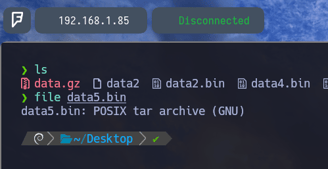
$ file data5.bin - Por lo tanto vamos a aplicar otro file para comprobar ante que nos enfrentamos. Y como podemos observar es un archivo comprimido de tipo tar
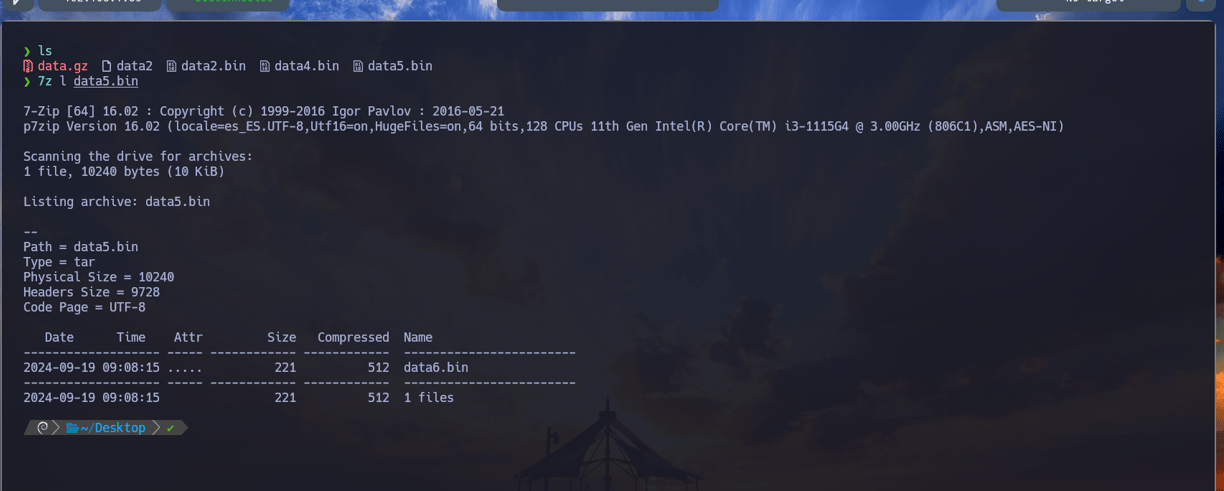
$ 7z l data5.bin - Ahora comprobando que hay dentro del archivo data5.bin podemos observar que se encuentra un nuevo archivo data6.bin. Por lo tanto vamos a descomprimirlo
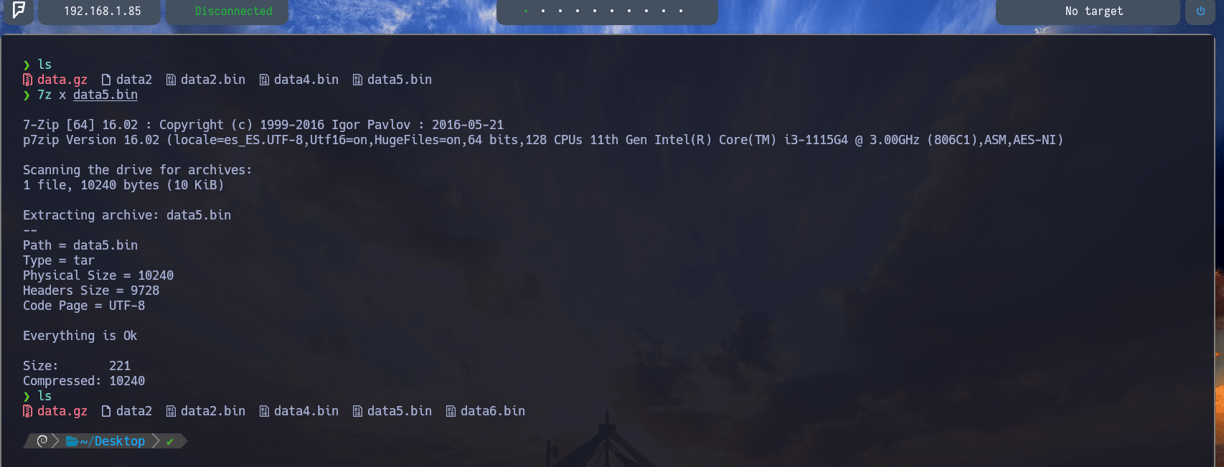
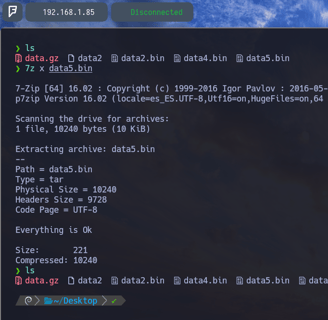
$ 7z x data5.bin - Lo extraemos y podemos observar que ya lo tenemos en nuestra ruta actual data6.bin

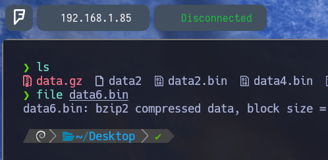
$ file data6.bin - Entonces volvemos a aplicar file para comprobar ante que archivo nos enfrentamos, y como podemos ver, es un archivo comprimido de tipo bzip2
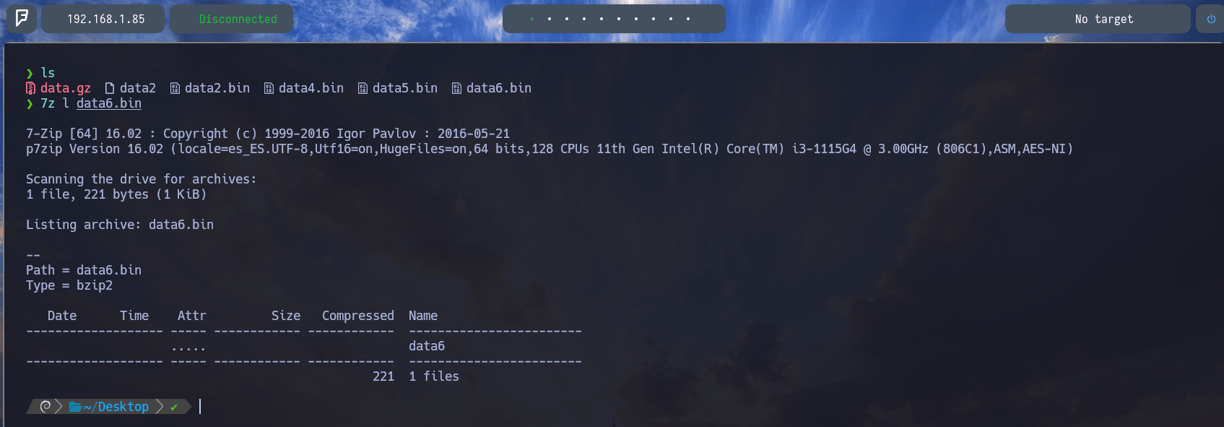
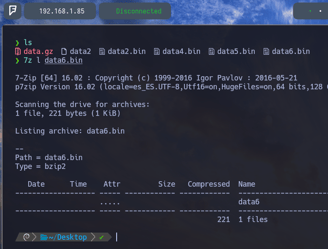
$ 7z l data6.bin - Ahora comprobando que hay dentro del archivo data6.bin podemos comprobar que nos encontramos con un nuevo archivo data6. Por lo tanto vamos a descomprimirlo para comprobar que nos encontramos
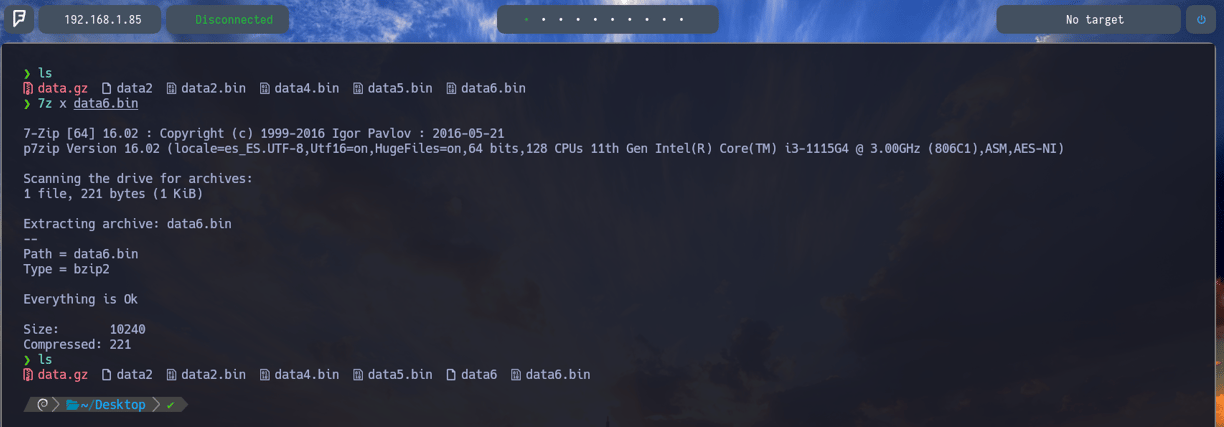
$ 7z x data6.bin - Y como vemos lo extraemos y ya lo volvemos a tener en nuestra ruta actual data6

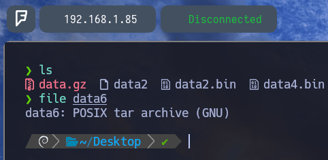
$ file data6 - Volvemos a aplicar un file para comprobar ante que nos enfrentamos, y como podemos observar. Es un archivo comprimido de tipo tar.
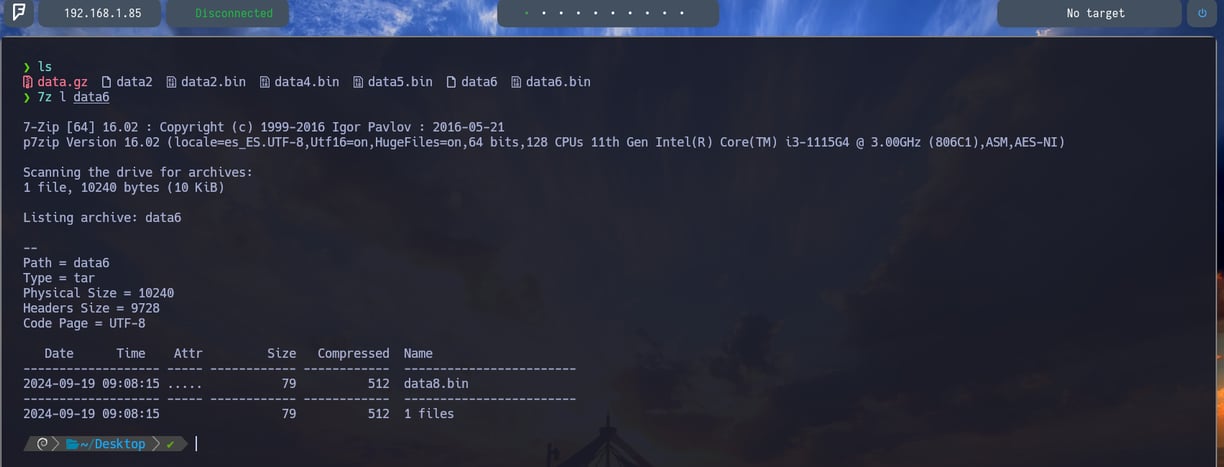
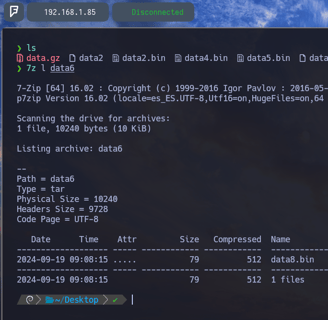
$ 7z l data6 - Para volver a comprobar que contiene este comprimido. Y como vemos dentro observamos otro nuevo archivo data8.bin Por lo tanto vamos a descomprimirlo para poder ver ante que nos enfrentamos
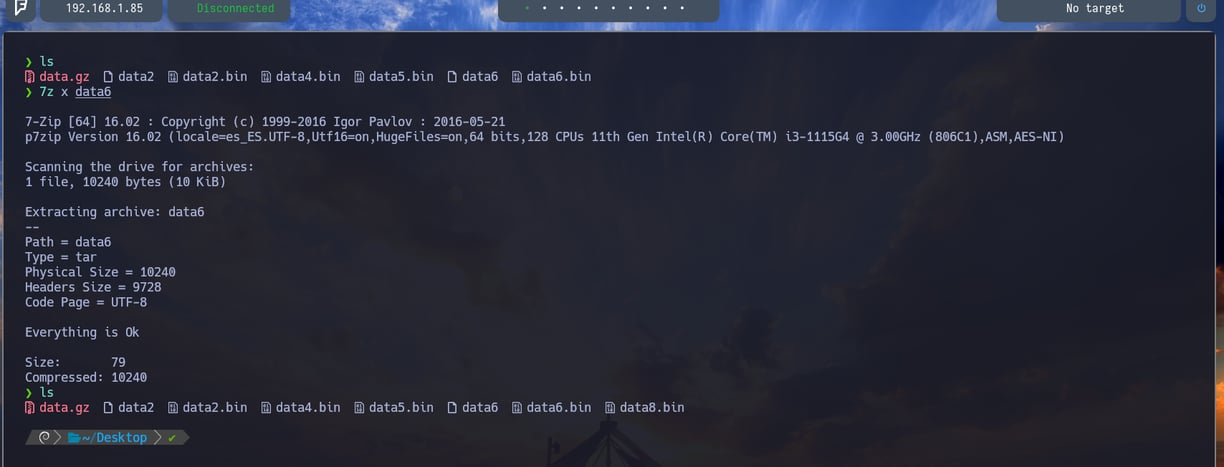
$ 7z x data6 - Lo extraemos y como vemos ya tenemos en nuestra ruta actual data8.bin

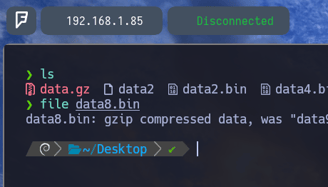
$ file data8.bin - Volvemos a aplicarle un file para comprobar ante que nos enfrentamos. Y como vemos es un archivo comprimido de tipo gzip
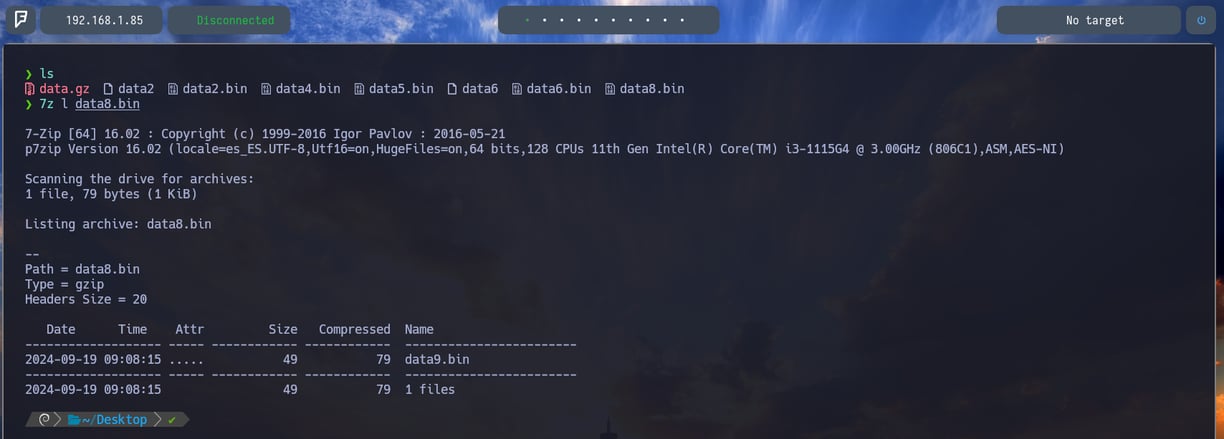
$ 7z l data8.bin - Volvemos a aplicar 7z l para listar el contenido que tiene dentro el comprimido por si acaso. Y vemos que nos encontramos con un archivo nuevo data9.bin. Por lo tanto vamos a descomprimirlo para ver ante que nos enfrentamos...
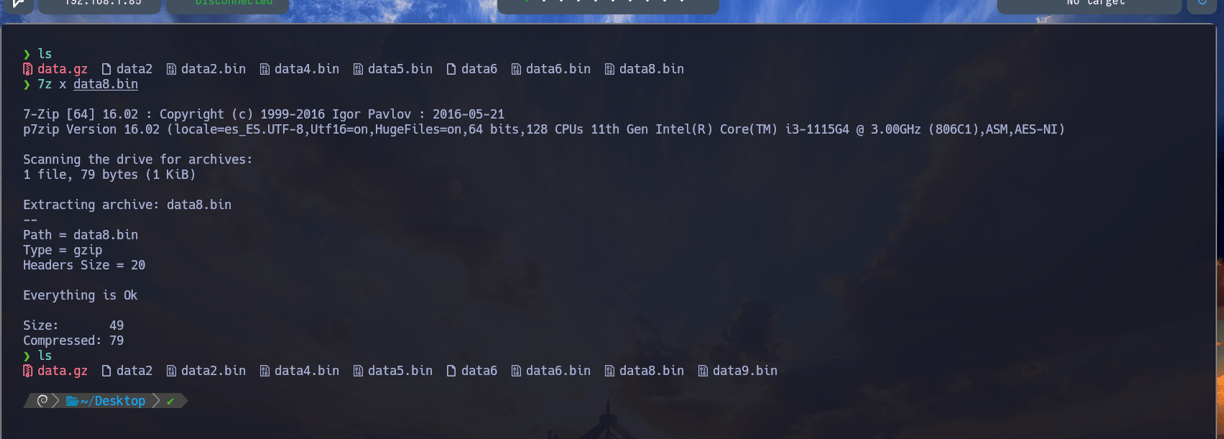
$ 7z x data8.bin - Volvemos a extraer el archivo y como vemos ya lo tenemos en nuestra ruta actual. Data9.bin

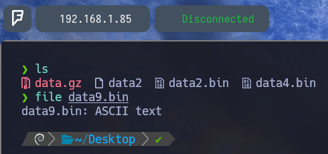
$ file data9.bin - Volvemos a aplicar file para comprobar ante que nos enfrentamos y esta vez no es un comprimido, sino que un archivo de texto ASCII. Vamos a ver su contenido

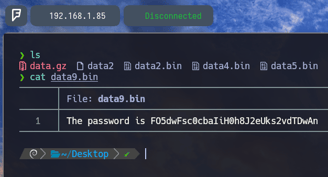
Y por fin como podemos comprobar ya hemos logrado la contraseña:
FO5dwFsc0cbaIiH0h8J2eUks2vdTDwAn
Pero esto ha sido muy largo de realizar, poco efectivo, y tedioso... Vamos a probar otra forma de lograr lo mismo en menos tiempo y solo con un poco de esfuerzo... Por lo tanto vamos a crear un script en bash para poder automatizar todo esto y hacerlo de una manera mucho más rápida...

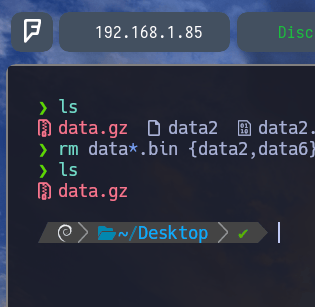
$ rm data*.bin {data2,data6} - Con rm le indicamos que queremos eliminar todos los archivos data*.bin es decir todos los archivos que empiecen por la palabra data y acaben en .bin además le agregamos el parámetro {data2,data6} para con esto indicarle que queremos eliminar un conjunto de archivos. Es decir data2 y data6 . Y como vemos se eliminan todos excepto el archivo padre data.gz

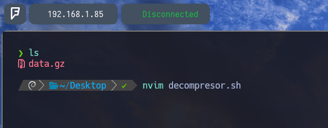
Entonces vamos a crear un script en bash con el comando $ nvim decompresor.sh Este será nuestro primer script para algunos, y para otros uno más que sumar a nuestra lista de aprendizaje

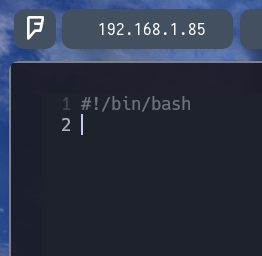
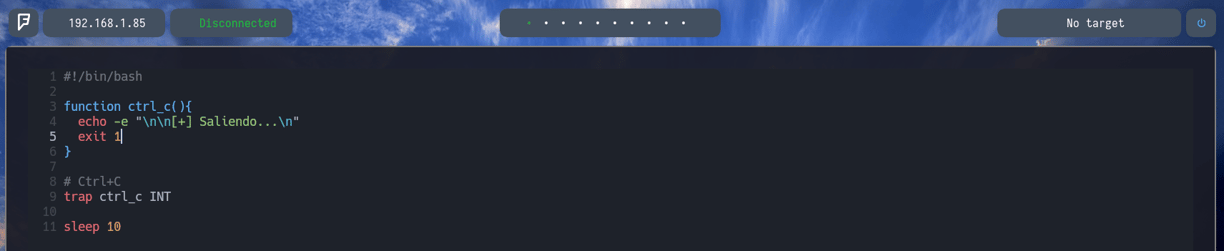
Entonces empezando a crear el script: Para poder empezar a crear nuestro script en bash, debemos escribir lo siguiente en la primera línea #!/bin/bash para que el mismo archivo sepa que nos enfrentamos a un archivo de tipo bash y que todo lo que escribamos seguidamente esta escrito en bash.

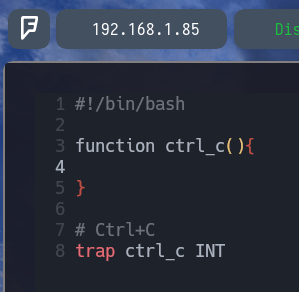
Ahora con trap ctrl_c INT lo que logramos es "decirle al programa: Vale cuando presione CTRL + C quiero que el flujo del programa se redirija hacia la función CTRL_C que hemos determinado arriba, por lo tanto haga lo que ponga en la función al presionar CTRL + C"
Como vemos donde indica function ctrl_c(){ } Pondremos que queremos que haga la función ctrl_c, de la siguiente manera...

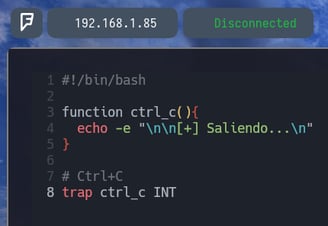
echo -e "\n\n[+] Saliendo ...\n" Con esto le indicamos a la función que queremos que ejecute el comando echo -e Entonces guardamos el archivo. Haciendo un Esc + SHIFT + : Y escribimos wq! Para guardar y salir. Y haremos lo siguiente...

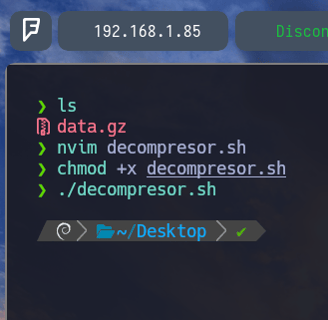
$ chmod +x decompresor.sh Para darle permisos de ejecución y lo ejecutamos. Pero como vemos no nos ha dado tiempo a presionar CTRL + C. Esto es debido a lo siguiente...

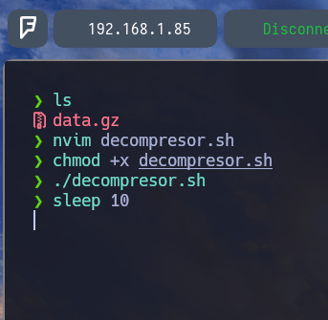
Como vemos si aplicamos un $ sleep 10 Lo que logramos es que la terminal se quede pensando 10 segundos, como en estado durmiente... Por lo tanto podemos aplicarlo a nuestro script para que podáis comprobar que realmente funciona el CTRL + C

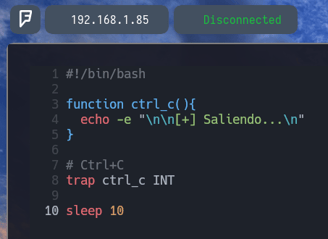
Como vemos lo aplicamos al final del archivo y si volvemos a ejecutarlo veremos lo siguiente...

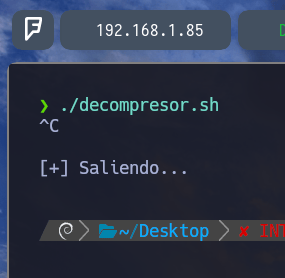
Ahora si lo volvemos a ejecutar como veremos, el script lo que hará será esperar 10 segundos. Pero yo antes de que acaben esos 10 segundos lo que realizo es un CTRL + C y se ejecuta la función CTRL + C Ya que con trap ctrl_c INT lo habíamos capturado anteriormente para que como output podamos decir que nos salga [+] Saliendo... Esto lo suelo hacer porque me gusta capturar el CTRL + C en los scripts que realizo
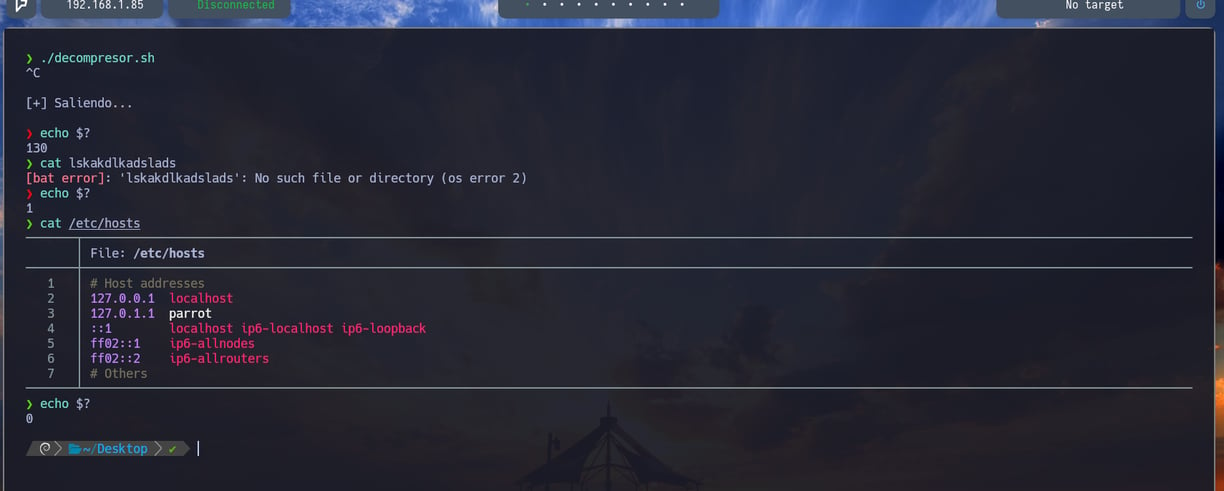
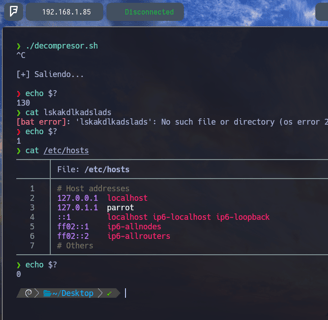
Bien, ahora como podemos comprobar si ejecutamos un $ echo $? Esto nos permite ver el código de estado del último comando ejecutado. Esto nos permite saber si el comando se ha ejecutado de manera exitosa o no, mediante los códigos que nos aparecen al ejecutar echo $? entonces si vemos que el código de estado es igual a 0 el código de estado es exitoso. Pero en cambio si vemos un numero superior a 0 entonces el código de estado es erróneo. Como vemos en la imagen, si ejecutamos un $ cat aklldkaskdlksa y volvemos a hacer echo $? el código de estado es igual a 1 porque es un error como vemos. Y si ejecutamos el script y hacemos un echo $? el código de estado es igual a 130 por lo tanto..
Yo cuando presione la tecla CTRL + C Quiero indicarle al script que es un error, por lo tanto lo indicaremos con el código de estado 1... Si no ejecutamos CTRL + C y el script finaliza exitosamente, el resultado debería ser 0 como código de estado
Como vemos en la función agregamos exit 1 para indicarle que queremos que el código de estado sea 1, como vemos en la siguiente imagen...

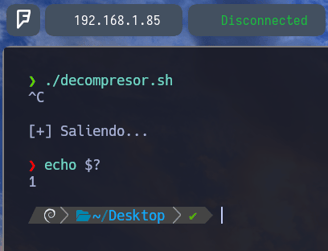
También como podemos comprobar en la flecha de la izquierda del comando echo $? esta en rojo y el resto en verde. Esto se debe a que el comando que hemos ejecutado anteriormente, nos otorga un código de estado no exitoso. Así es como lo tengo yo configurado en la powerlevel10k que seria mi terminal
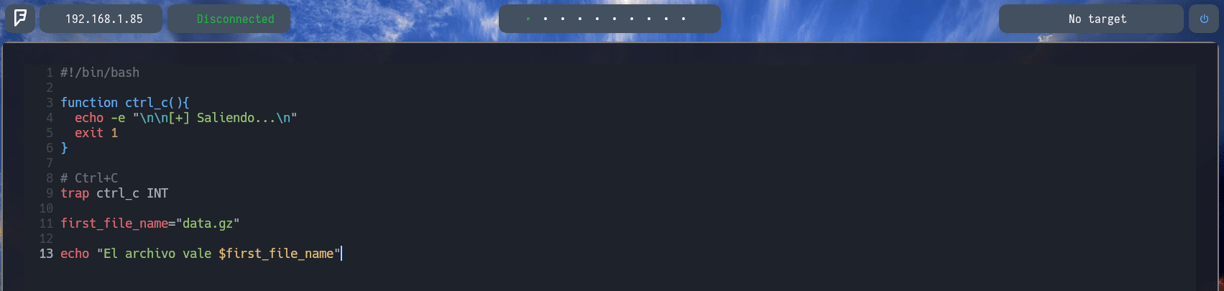
Ahora, nuestra función sería lograr crear el script para poder descomprimir todos los archivos de manera automática. Entonces ¿Por donde empezaríamos? Pues muy fácil, lo que haremos será decirle al script por donde debe empezar a descomprimir. Por lo tanto el primer archivo es data.gz. Bien, una vez sabemos que archivo hay que descomprimir primero, vamos a agregarle un nombre a ese archivo, ese nombre sería una variable first_file_name o como queramos llamarla. Cuyo valor será igual a data.gz como podemos ver en la imagen. Y si ahora por ejemplo vemos que si aplicamos un echo y hacemos una llamada a la variable como resultado nos dará data.gz Como vemos en el texto echo "El archivo vale $first_file_name". Entonces vamos a ver como se vería esto...

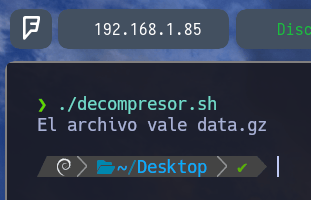
Como podemos comprobar vemos que el script decompresor.sh nos imprime en pantalla El archivo vale data.gz Tal y como le hemos ordenado anteriormente.
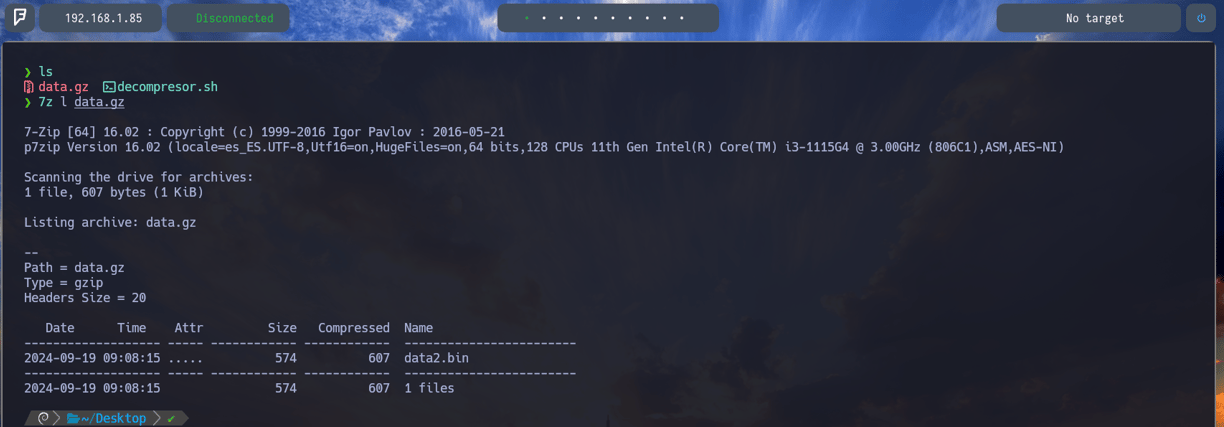
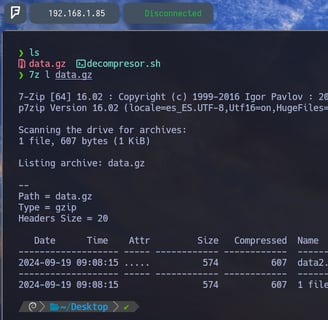
Ahora, bien sabemos que para poder descomprimir el siguiente archivo y poder llegar a la contraseña, debemos usar la herramienta 7z la cual nos ayudó anteriormente a poder listar y descomprimir los archivos. Entonces, lo que haremos será con 7z listar el contenido de data.gz con el fin, de lograr el nombre del siguiente archivo a descomprimir. Por lo tanto data2.bin como vemos en la imagen en la parte inferior, derecha. Entonces, nuestra misión será poder capturar el nombre del siguiente archivo dentro del script. Veamos como lo logramos...
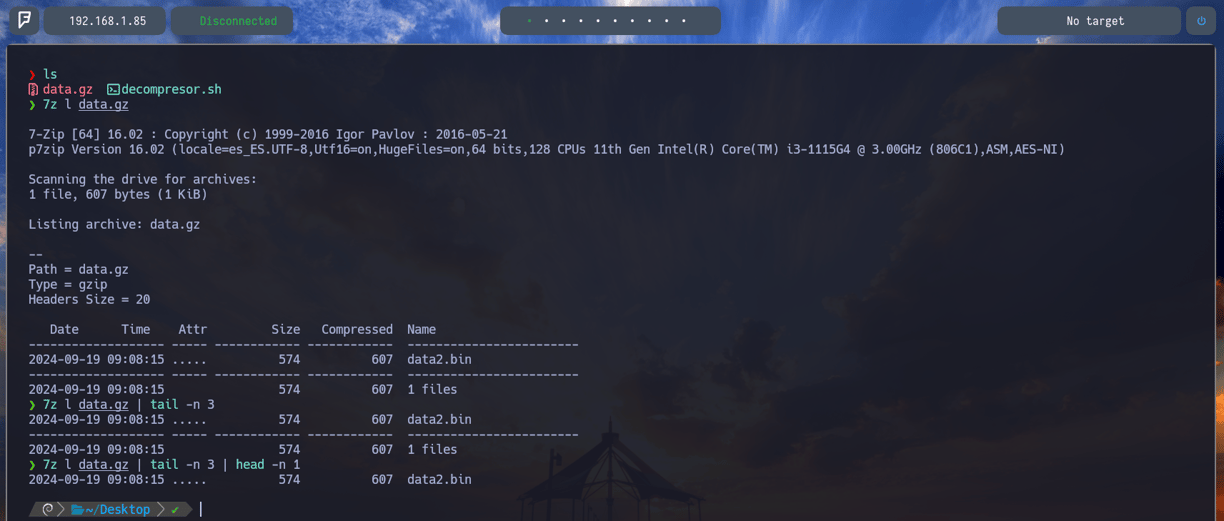
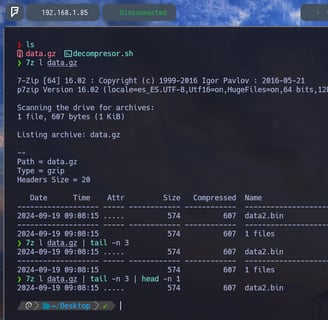
$ 7z l data.gz | tail -n 3 | head -n 1 - Ahora agregamos al comando 7z l data.gz el comando tail -n 3 para indicarle que queremos imprimir en pantalla las últimas 3 líneas del output del comando 7z l data.gz como vemos en la imagen superior. Seguidamente volvemos a realizar el mismo comando 7z l data.gz | tail -n 3 pero agregándole el comando head -n 1 para indicarle que solo queremos imprimir la primera línea del output del comando tail. Por lo tanto del comando 7z. Y como vemos en la imagen el output sería la línea que incluye el nombre del archivo... Pero con esto no hemos logrado solo imprimir el nombre del siguiente archivo, sino que toda la línea. Así que vamos a ver como logramos imprimir solo el nombre...

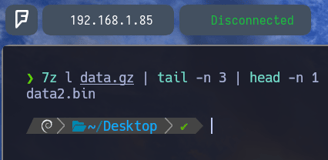
Entonces le agregamos al final el comando awk 'NF{print $NF}' Para como ya sabemos indicarle que solo queremos el último argumento de la línea. Que sería el nombre del archivo.
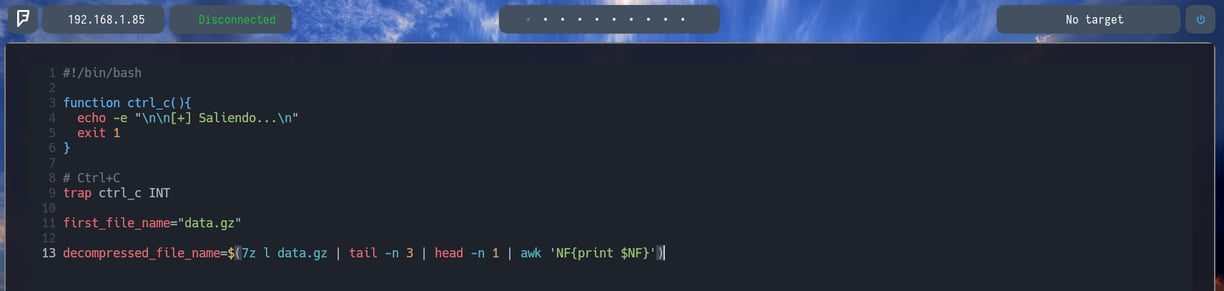
Bien ahora lo que haremos será crear otra variable con el nombre decompressed_file_name donde le indicaremos todo el comando que hemos ejecutado anteriormente 7z l data.gz | tail -n 3 | head -n 1 | awk 'NF{print $NF}' Por lo tanto decompressed_file_name=$(7z l data.gz | tail -n 3 | head -n 1 | awk 'NF{print $NF}' Con esto guardamos el nombre del siguiente archivo dentro de la variable decompressed_file_name que usaremos posteriormente.
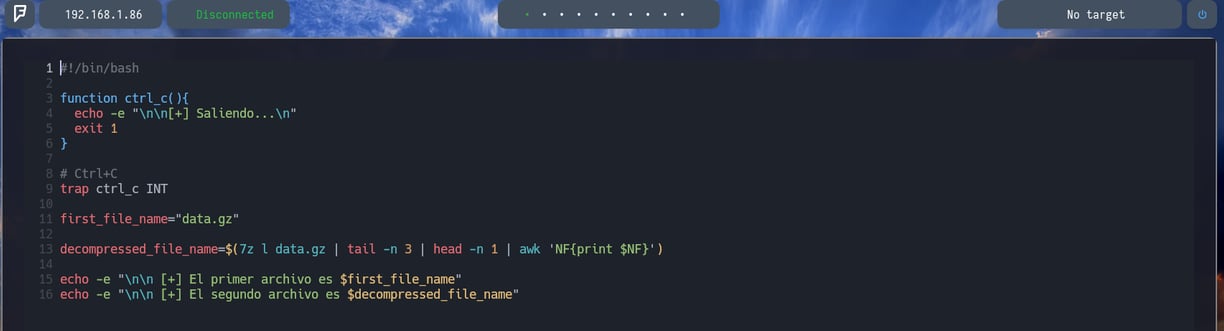
Como por ejemplo si en este caso realizamos un echo de estas 2 variables, podríamos ver lo siguiente...
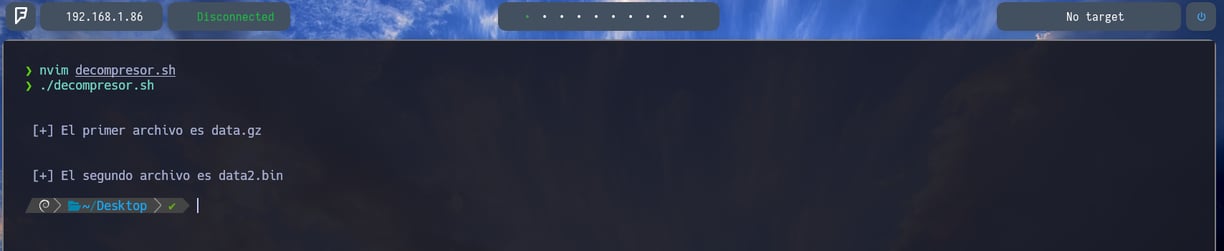
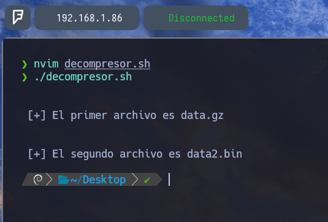
Como vemos en la imagen [+] El primer archivo es data.gz [+] El segundo archivo es data2.bin
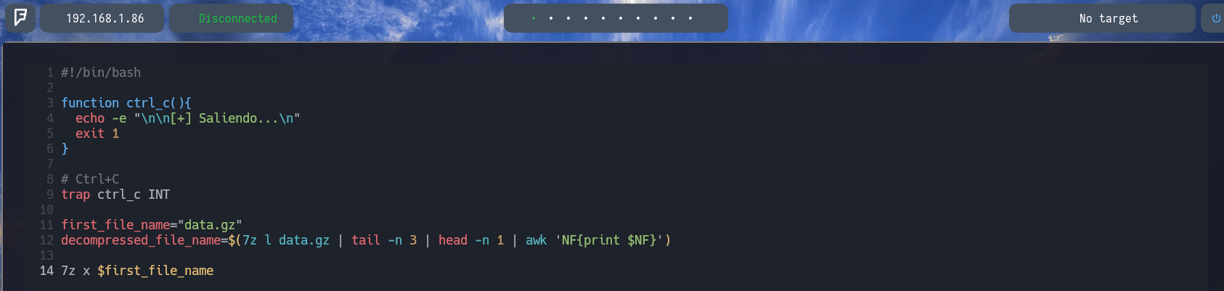
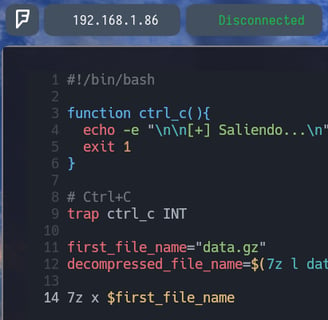
Ahora lo que haremos será descomprimir el archivo. Porque como hemos visto anteriormente, únicamente lo que hemos realizado ha sido listar el contenido que vamos a descomprimir. Pero sin llegar a hacerlo. Entonces agregaremos la siguiente función 7z x $first_file_name como vemos en la imagen.
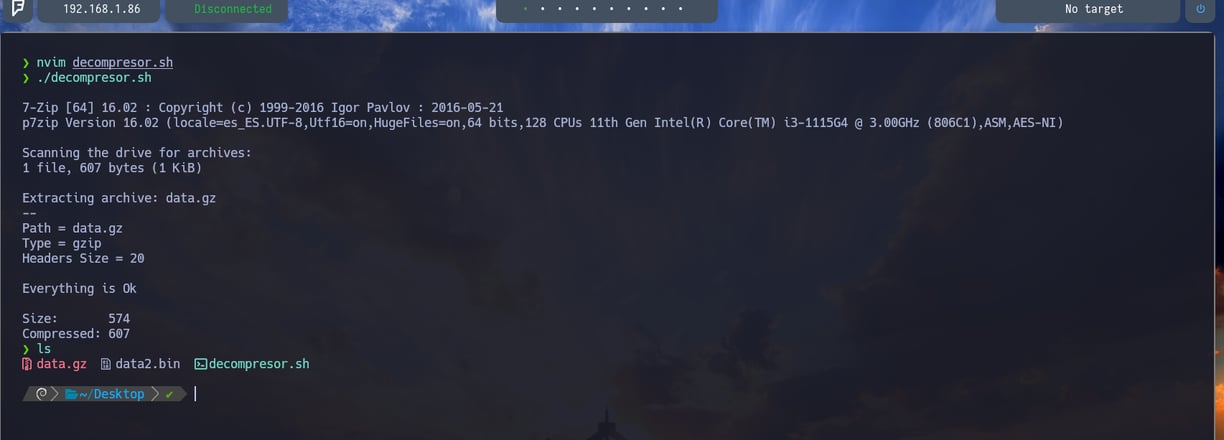
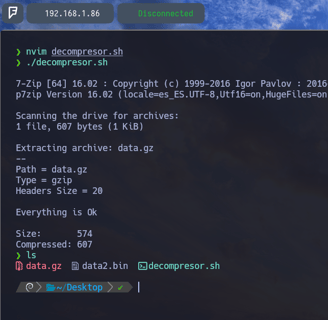
Bien, si ahora ejecutamos el script, como podemos observar nos descomprime el archivo perfectamente. Pero nos sale el output del comando 7z x $first_file_name el cual no queda bien y queremos ocultar. Por lo tanto vamos a ocultarlo...
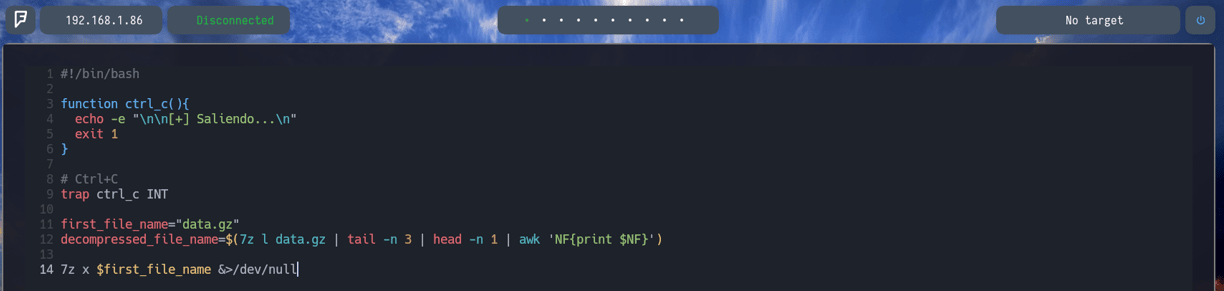
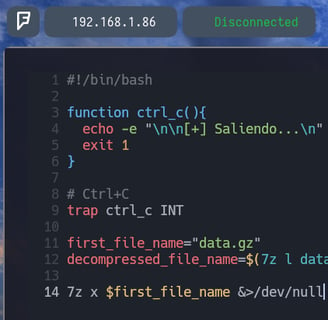
Le agregaremos al comando 7z x $first_file_name &>/dev/null con la finalidad de redirigir todo &> al archivo /dev/null Para que nos oculte la parte del output de dicho comando. Como vemos en la siguiente imagen...

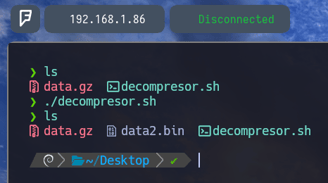
Bien, como podemos observar, ya no sale nada como output de dicho comando y el archivo data2.bin se ha ejecutado correctamente
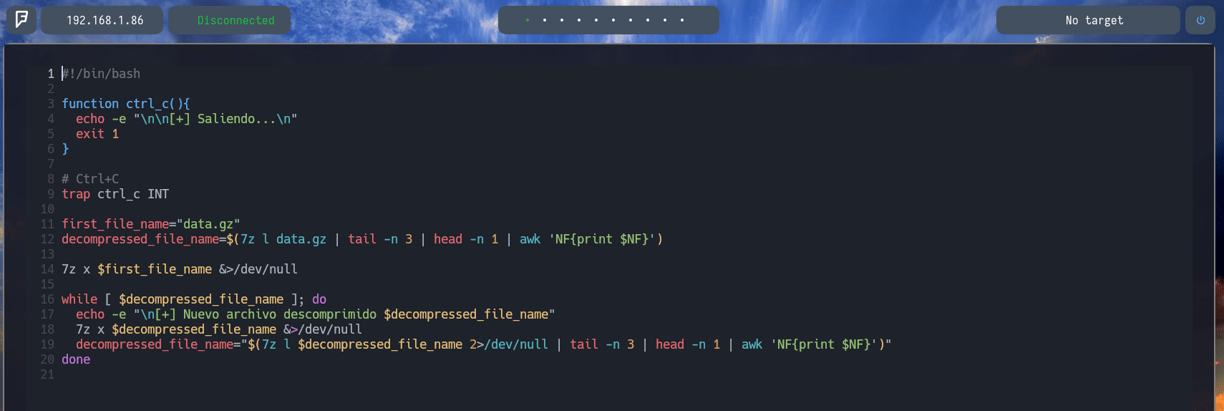
Ahora llegados a este punto. Lo que haría yo en mi caso sería utilizar la siguiente función para poder crear este script. Yo utilizaría while [ ]; do done Donde lo que haría sería while [ $decompressed_file_name ]; do Donde indico que mientras la variable $decompressed_file_name tenga contenido. Es decir se vaya ejecutando el comando 7z l data.gz, y sea correcto, ejecuta dicha variable. En caso contrario. Haz lo siguiente. Ejecuta el comando echo -e "\n[+] Nuevo archivo descomprimido $decompressed_file_name" Para ir sabiendo que archivos se van descomprimiendo. Seguidamente lo que haremos será que, como ya sabemos cual será el siguiente archivo a descomprimir. Lo vamos a extraer con 7z x $decompressed_file_name &>/dev/null Para poder descomprimirlo. Y redirigimos el output al /dev/null Entonces para finalizar vamos a listar el siguiente archivo con decompressed_file_name="$(7z l $decompressed_file_name 2>/dev/null | tail -n 3 | head -n 1 | awk 'NF{print $NF}')" Para poder indicar que del propio decompressed_file_name que sería el siguiente archivo a descomprimir queremos listar el siguiente archivo para descomprimirlo. Y que el STDERR del ultimo archivo que de error lo queremos ocultar. Por lo tanto se verá de la siguiente manera...
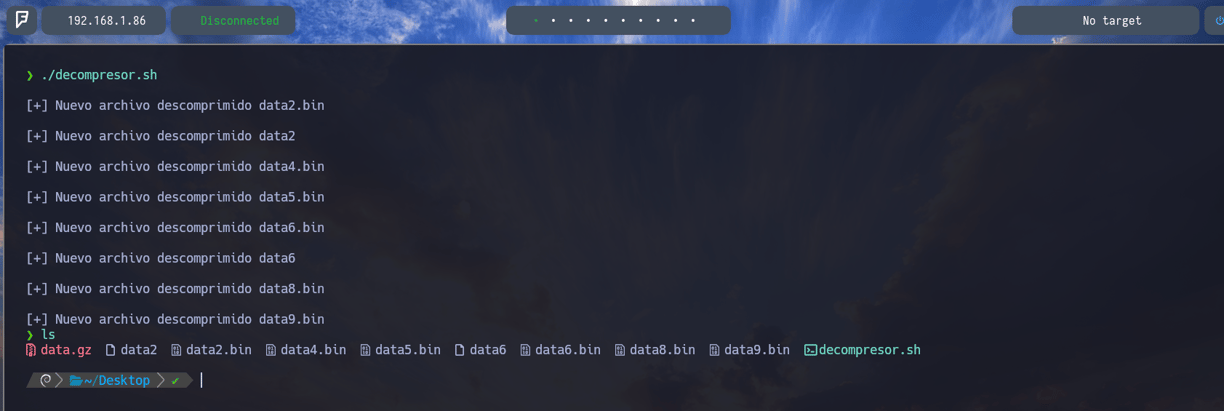
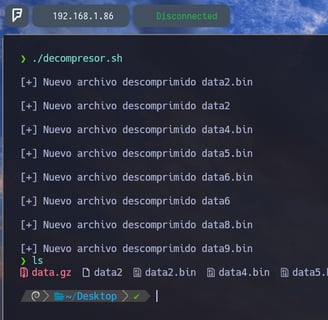
Como vemos se descomprimen todos los archivos sin problema alguno. Y si abrimos el ultimo archivo data9.bin podremos ver la contraseña.
FO5dwFsc0cbaIiH0h8J2eUks2vdTDwAn
Como vemos se descomprimen todos los archivos sin problema alguno. Y si abrimos el ultimo archivo data9.bin podremos ver la contraseña.
FO5dwFsc0cbaIiH0h8J2eUks2vdTDwAn