
Métodos de filtrado de datos [1-2]
3/24/20255 min read

Nuevamente volvemos a acceder a Bandit con el usuario 7. Bandit7 con el comando:
$ sshpass -p 'morbNTDkSW6jIlUc0ymOdMaLnOlFVAaj' ssh bandit7@bandit.labs.overthewire.org -p 2220

Y volvemos a aplicar la terminal xterm con el comando $ export TERM=xterm para nuevamente poder limpiar la terminal con CTRL + L
Vale llegados a este punto, vemos que bandit nos indica que la contraseña se encuentra en el archivo data.txt cerca de la palabra millonth. Así que vamos a ver como podemos encontrarla.

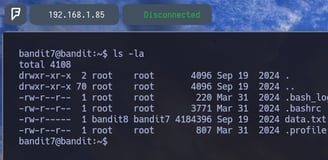
$ ls -la - Para poder comprobar si vemos el archivo data.txt que nos indica la página de bandit.
$ cat data.txt - Como vemos listando el contenido del archivo data.txt nos sería imposible encontrar la contraseña de manera manual. Por lo tanto vamos a realizar un grep para poder encontrar la linea donde se encuentra la contraseña...
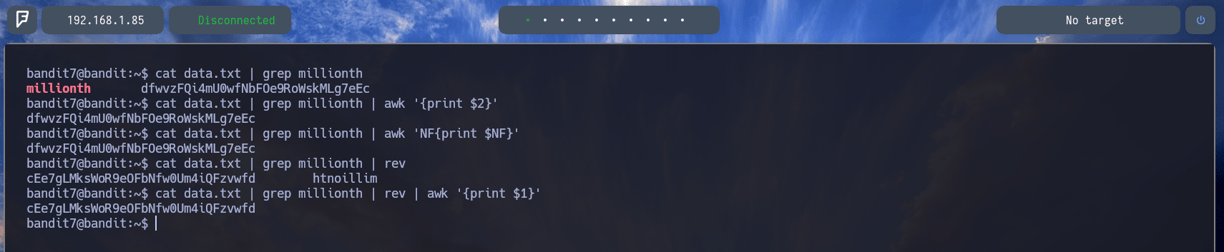
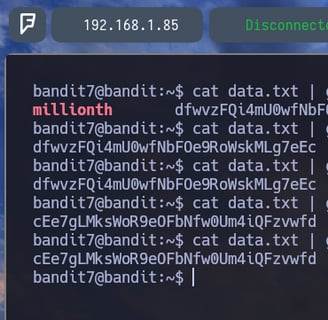
$ cat data.txt | grep millionth - Como podemos ver realizando un grep ya logramos la contraseña para el siguiente nivel. Pero os voy a enseñar diferentes maneras de poder lograrla:
$ cat data.txt | grep millionth | awk '{print $2}' - Donde con awk le indicamos que queremos solo el segundo argumento, es decir la contraseña
$ cat data.txt | grep millionth | awk 'NF{print $NF}' - Para indicar que solo queremos que nos imprima en pantalla el argumento final, es decir la contraseña.
$ cat data.txt | grep millionth | rev | awk '{print $1}' - Para indicarle que queremos que reversee con rev todo el contenido y que nos coja solo el primer argumento, es decir la contraseña y al final si quisieramos que se viera de manera correcta agregando el parámetro rev de nuevo...
dfwvzFQi4mU0wfNbFOe9RoWskMLg7eEc

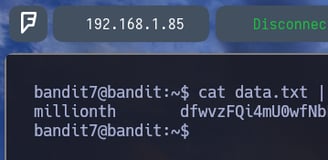
Como método adicional, podemos nosotros probar que con el comando cut nos detecta que no nos deja imprimir en pantalla la contraseña. Por eso usamos awk. Os lo muestro en el ejemplo de arriba, en la imagen. Si hacemos un $ cut -d ' ' -f 1 con cut indicamos que queremos cortar el output, tomando como -d delimitador el espacio ' ' y cogiendo el -f fragmento numero 1 nos indica que no. ¿Y esto a que se debe? A que como espacios no solo hay 1 solo, hay varios, entonces vamos a ver como se puede comprobar esto...

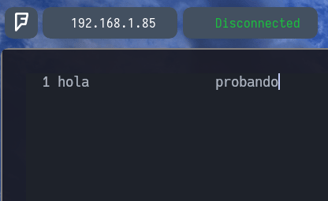
Voy a probar creando un archivo donde introduzco la palabra hola junto a varios espacios y seguidamente probando. Para que podáis ver lo siguiente...
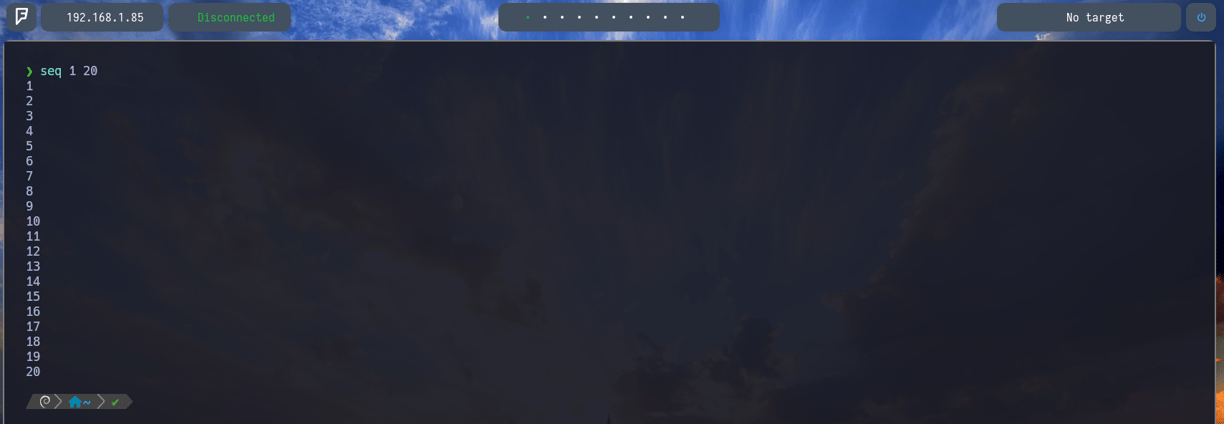
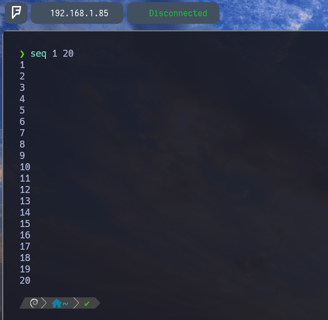
Nosotros a la hora de querer crear una secuencia de números, podemos usar la variable en bash "seq" y indicarle que secuencia queremos que nos imprima en pantalla. En mi caso seq 1 20 como vemos en la imagen...
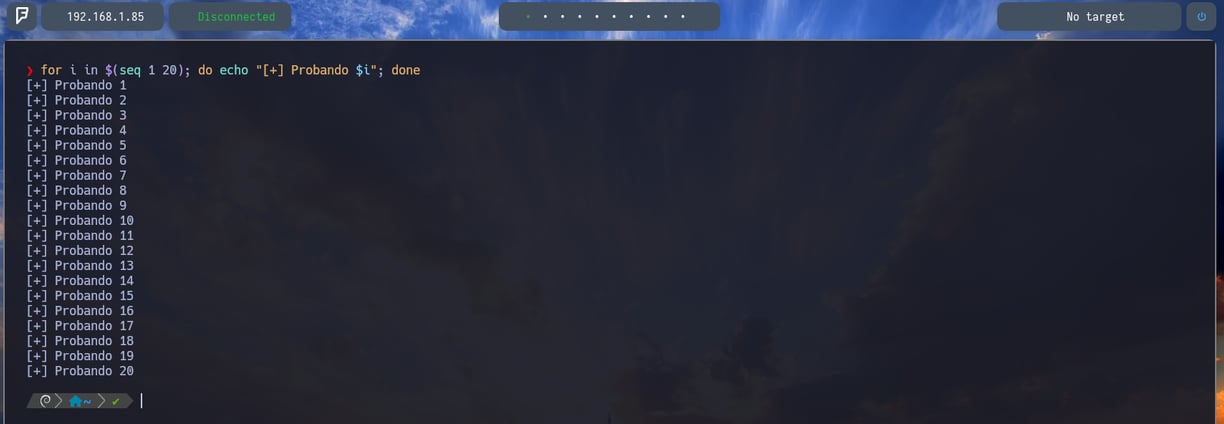
Ahora nosotros podemos crear una variable de entorno con for que lo veremos más adelante. Donde a for le indicamos que dentro de i haya una secuencia del 1 al 20 con $(seq 1 20) donde se almacena dentro de i cada secuencia que definamos, es decir de la numero 1 a la numero 20. Seguidamente hacemos un do para que una vez guardada la secuencia en i nos haga lo siguiente ( Nos imprima en pantalla con echo "[+] Probando $i" + la variable i con $i entonces i = a 1,2,3,4,5,6,7,8,.... así sucesivamente hasta el 20. Y por último done. Por lo tanto veremos el output de la imagen, que como resultado obtenemos lo siguiente... Una cadena de lineas Probando nuestra secuencia previamente definida...

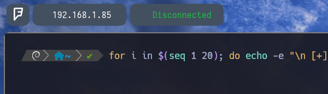
$ for i in $(seq 1 20); do echo -e "\n [+] Probando en $i:\n"; cat example | cut -d ' ' -f $i; done - Ahora nos explota la cabeza... Pero es bastante sencillo de explicar y de entender...
Visto lo anterior cambiamos la sección del do donde le aplicamos un echo -e para que nos interprete expresiones y carácteres especiales, "\n [+] Probando en $i:\n" Donde con \n le indicamos que queremos que nos haga un salto de linea y con la expresión Probando en $i Llamamos a la variable i para que nos lo imprima 20 veces. Para poder con esto comprobar en que espacio dentro del archivo example se encuentra la palabra "probando" para luego poder hacer un cut... Seguidamente vemos que en el apartado siguiente ; cat example | cut -d ' ' -f $i le indicamos a la variable que queremos que haga un cat de example para que busque dentro de dicho archivo y con cut que tome como delimitador los espacios, para que vaya contando espacio por espacio desde hola hasta probando cuantos hay, y nos lo imprima en pantalla junto con la variable $i para que lo imprima 20 veces y dentro de esas 20 nos encuentre en que espacio se encuentra la palabra probando...
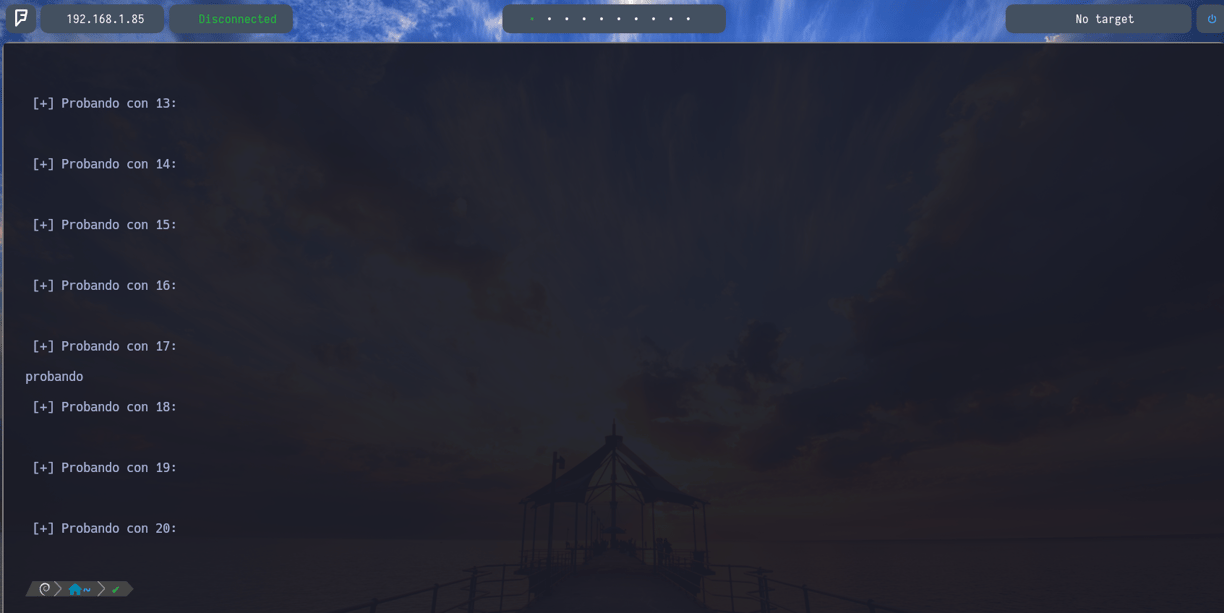
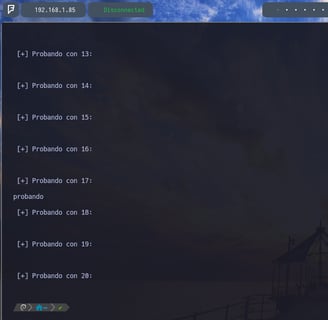
Como vemos en pantalla nos va imprimiendo [+] Probando con 1: , [+] Probando con 2: , [+] Probando con 3: ... Y así continuamente hasta el 20, hasta encontrar la palabra probando, que se encuentra en el espacio 17, es decir he echo 17 espacios después de hola para escribir la palabra probando...
Por lo tanto ahora podemos hacer lo siguiente:
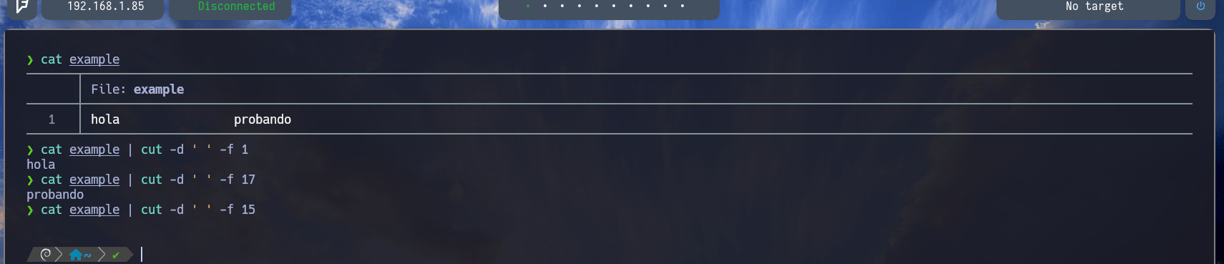
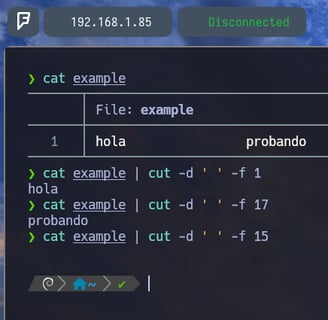
Volvemos a hacer un cat, para ver que ahí siguen los espacios, entonces si ahora hacemos un $ cat example | cut -d ' ' -f 1 nos imprime hola como primer argumento , y si hacemos un cut del espacio número 17 nos imprimirá probando $ cat example | cut -d ' ' -f 17 y si probamos aplicar lo mismo para el argumento número 15 nos detectará que no hay nada en el espacio 15.
Esto es un ejemplo práctico de fuerza bruta para poder encontrar lo que deseemos en base a esta lógica...
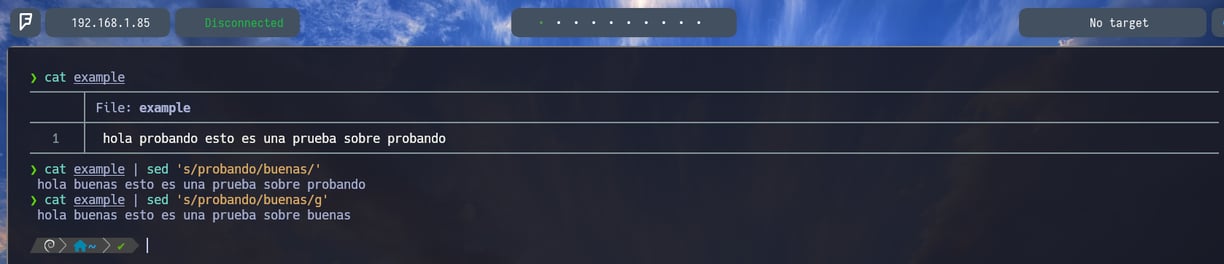
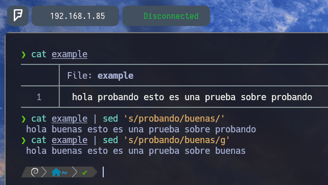
Y por último a explicar, podemos aplicar substituciones en archivos de manera temporal con sed, sed es una herramienta se substitución bastante práctica y fácil de usar. La podemos emplear de la siguiente manera: Haciendo un cat del archivo example vemos el texto siguiente: hola probando esto es una prueba sobre probando. Si le aplicamos sed podemos cambiar palabras, por ejemplo: $ cat example | sed 's/probando/buenas/' Donde indicamos con el parámetro s/ que queremos substituir seguidamente de la palabra a sustituir que sería la palabra probando por la palabra buenas, tal y como vemos en la imagen de arriba. Pero cuidado como vemos solo se aplica el cambio en el primer probando en lugar de aplicarse a todos. Esto es porque como vemos en la imagen al final del comando sed, debemos aplicar la letra g: $ sed 's/probando/buenas/g' y como vemos se aplica el cambio en todas las palabras probando.